Home >> Blog >> 淺談 BERT - NLP 的最先進語言模型
淺談 BERT - NLP 的最先進語言模型
BERT (Bidirectional Encoder Representations from Transformers) 是Google AI Language 的研究人員最近發表的一篇論文。它通過在包括問答 (SQuAD v1.1)、自然語言推理 (MNLI) 等在內的各種 NLP 任務中展示最先進的結果,在機器學習社群引起了轟動。
BERT 的關鍵技術創新是將流行的注意力模型 Transformer 的雙向訓練應用於語言建模。這與以前從左到右或從左到右和從右到左組合的訓練中查看文本序列的努力形成對比。論文的結果表明,雙向訓練的語言模型比單向語言模型可以更深入地感知語言上下文和流。在論文中,研究人員詳細介紹了一種名為 Masked LM (MLM) 的新技術,該技術允許在以前不可能的模型中進行雙向訓練。
背景
在計算機視覺領域,研究人員反覆展示了遷移學習的價值——在已知任務上預訓練神經網絡模型,例如 ImageNet,然後進行微調——使用訓練好的神經網絡作為新的特定用途模型。近年來,研究人員已經證明,類似的技術可以用於許多自然語言任務例如SEO搜尋引擎優化的內容行銷項目已被AI 自動產生的內容取代。
另一種在 NLP 任務中也很流行並在最近的 ELMo 論文中得到例證的方法是基於特徵的訓練。在這種方法中,預訓練的神經網絡生成詞嵌入,然後將其用作 NLP 模型中的特徵。
BERT 的工作原理
BERT 使用了 Transformer,這是一種學習文本中單詞(或子詞)之間上下文關係的注意力機制。在其普通形式中,Transformer 包括兩個獨立的機制——一個讀取文本輸入的編碼器和一個為任務生成預測的解碼器。由於 BERT 的目標是生成語言模型,因此只需要編碼器機制。谷歌的一篇論文中描述了 Transformer 的詳細工作原理。
與按順序(從左到右或從右到左)讀取文本輸入的定向模型相反,Transformer 編碼器一次讀取整個單詞序列。因此它被認為是雙向的,儘管說它是非定向的會更準確。這一特性允許模型根據其所有周圍環境(單詞的左側和右側)來學習單詞的上下文。
下圖是 Transformer 編碼器的高級描述。輸入是一系列標記,它們首先嵌入到向量中,然後在神經網絡中進行處理。輸出是一個大小為 H 的向量序列,其中每個向量對應一個具有相同索引的輸入標記。
在訓練語言模型時,定義預測目標是一個挑戰。許多模型預測序列中的下一個單詞(例如“孩子從___回家”),這種定向方法本質上限制了上下文學習。為了克服這一挑戰,BERT 使用了兩種訓練策略:
蒙面LM(傳銷)
在將單詞序列輸入 BERT 之前,每個序列中 15% 的單詞被替換為 [MASK] 標記。然後,該模型嘗試根據序列中其他非掩碼單詞提供的上下文來預測掩碼單詞的原始值。用技術術語來說,輸出詞的預測需要:
- 在編碼器輸出之上添加一個分類層。
- 將輸出向量乘以嵌入矩陣,將它們轉換為詞彙維度。
- 用 softmax 計算詞彙表中每個單詞的概率。
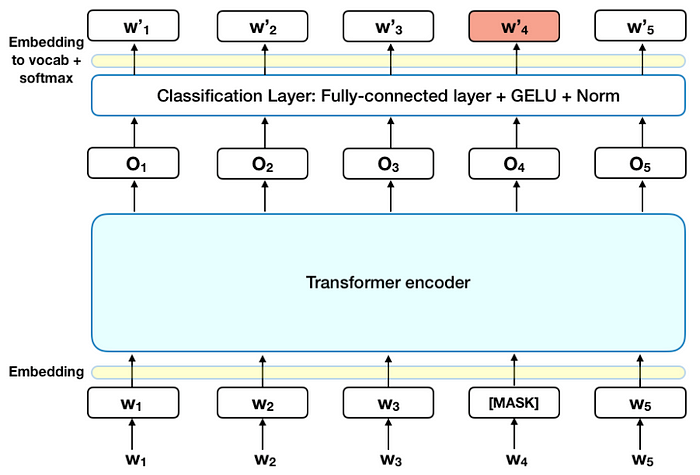
BERT 損失函數只考慮了對掩碼值的預測,而忽略了對非掩碼詞的預測。因此,該模型的收斂速度比定向模型慢,這一特徵被其增強的上下文感知所抵消。
注意:在實踐中,BERT 的實現稍微複雜一些,並沒有取代所有 15% 的掩碼詞。有關其他信息,請參閱附錄 A。
下一句預測(NSP)
在 BERT 訓練過程中,模型接收成對的句子作為輸入,並學習預測該對中的第二個句子是否是原始文檔中的後續句子。在訓練期間,50% 的輸入是一對,其中第二個句子是原始文檔中的後續句子,而在另外 50% 的輸入中,從語料庫中隨機選擇一個句子作為第二個句子。假設是隨機句子將與第一句斷開連接。
為了幫助模型在訓練中區分兩個句子,輸入在進入模型之前按如下方式處理:
- 在第一句的開頭插入一個 [CLS] 標記,在每個句子的結尾插入一個 [SEP] 標記。
- 將指示句子 A 或句子 B 的句子嵌入添加到每個標記中。句子嵌入在概念上類似於詞彙表為 2 的標記嵌入。
- 位置嵌入被添加到每個標記以指示其在序列中的位置。Transformer 論文中介紹了位置嵌入的概念和實現。
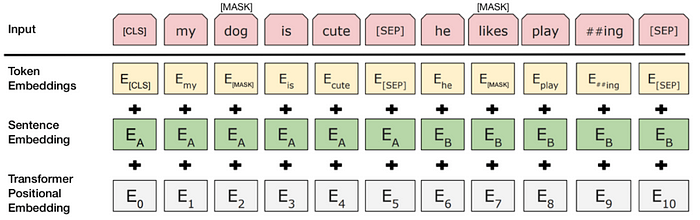
為了預測第二個句子是否確實與第一個句子相關,執行以下步驟:
- 整個輸入序列通過 Transformer 模型。
- 使用簡單的分類層(權重和偏差的學習矩陣)將 [CLS] 標記的輸出轉換為 2×1 形狀的向量。
- 用 softmax 計算 IsNextSequence 的概率。
在訓練 BERT 模型時,Masked LM 和 Next Sentence Prediction 一起訓練,目標是最小化這兩種策略的組合損失函數。
如何使用 BERT(微調)
將 BERT 用於特定任務相對簡單:
BERT 可用於多種語言任務,同時僅在核心模型中添加了一小層:
- 情感分析等分類任務的完成與 Next Sentence 分類類似,方法是在 [CLS] 令牌的 Transformer 輸出之上添加一個分類層。
- 在問答任務(例如 SQuAD v1.1)中,軟體接收有關文本序列的問題,並且需要在序列中標記答案。使用 BERT,可以通過學習兩個標記答案開始和結束的額外向量來訓練問答模型。
- 在命名實體識別 (NER) 中,軟體接收文本序列並需要標記文本中出現的各種類型的實體(人、組織、日期等)。使用 BERT,可以通過將每個標記的輸出向量輸入到預測 NER 標籤的分類層來訓練 NER 模型。
在微調訓練中,大多數超參數與 BERT 訓練中保持一致,論文對需要調優的超參數給出了具體指導(第 3.5 節)。BERT 團隊已經使用這種技術在各種具有挑戰性的自然語言任務上取得了最先進的結果。
外賣
- 模型大小很重要,即使規模很大。BERT_large 擁有 3.45 億個參數,是同類模型中最大的。它在小規模任務上明顯優於 BERT_base,BERT_base 使用相同的架構,“只有”1.1 億個參數。
- 有了足夠的訓練數據,更多的訓練步驟 == 更高的準確度。例如,在 MNLI 任務上,與具有相同批量大小的 500K 步訓練相比,在 1M 步(128,000 字批量大小)上訓練時,BERT_base 準確度提高了 1.0%。
- BERT 的雙向方法 (MLM) 的收斂速度比從左到右的方法要慢(因為每批中僅預測 15% 的單詞),但經過少量預訓練步驟後,雙向訓練的性能仍然優於從左到右的訓練。
結論
BERT 無疑是使用機器學習進行自然語言處理的一個突破。它平易近人並允許快速微調的事實可能會在未來允許廣泛的實際應用。在本摘要中,我們試圖描述論文的主要思想,同時不沉迷於過多的技術細節。對於那些希望深入了解的人,我們強烈建議您閱讀全文和其中引用的輔助文章。另一個有用的參考是BERT 源代碼和模型,它涵蓋了 103 種語言,並由研究團隊作為開源慷慨地發布。
附錄 A — 字掩碼
在 BERT 中訓練語言模型是通過預測輸入中 15% 的標記來完成的,這些標記是隨機挑選的。這些標記按如下方式進行預處理——80% 用“[MASK]”標記替換,10% 用隨機詞替換,10% 使用原始詞。導致作者選擇這種方法的直覺如下(感謝來自 Google 的 Jacob Devlin 的洞察力):
- 如果我們在 100% 的時間內使用 [MASK],模型不一定會為非屏蔽詞生成良好的標記表示。非掩碼標記仍用於上下文,但該模型針對預測掩碼詞進行了優化。
- 如果我們在 90% 的時間使用 [MASK] 並在 10% 的時間使用隨機詞,這將告訴模型觀察到的詞永遠不會正確。
- 如果我們在 90% 的時間使用 [MASK] 並在 10% 的時間保持相同的單詞,那麼模型可以簡單地複制非上下文嵌入.
沒有對這種方法的比率進行消融,並且使用不同的比率可能效果更好。此外,模型性能沒有通過簡單地屏蔽 100% 的選定標記來測試。