Home >> Blog >> 一起了解yolov4
完成一天的SEO搜尋引擎優化專案進度後,讓我們一起來了解yolov4。
一起了解yolov4
是的OLO代表你只看一次。_ _ _ _ YOLO 是最先進的實時對象檢測系統。它是由約瑟夫·雷德蒙開發的。它是一種實時物體識別系統,可以在一幀內識別多個物體。隨著時間的推移,YOLO 已經演變成更新的版本,即 YOLOv2、YOLOv3 和 YOLOv4。
YOLO 使用了與以前的其他檢測系統完全不同的方法。它將單個神經網絡應用於完整圖像。該網絡將圖像劃分為多個區域,並預測每個區域的邊界框和概率。這些邊界框由預測概率加權。
YOLO的基本思想如下圖所示。YOLO 將輸入圖像劃分為 S × S 網格,每個網格單元負責預測以該網格單元為中心的對象。
每個網格單元預測 B 個邊界框和這些框的置信度分數。這些置信度分數反映了模型對盒子包含對象的信心以及它認為盒子預測的準確度。
與基於分類器的系統相比,YOLO 模型有幾個優點。它可以識別單個幀中的多個對象。它在測試時查看整個圖像,因此它的預測是由圖像中的全局上下文通知的。它還通過單個網絡評估進行預測,這與 R-CNN 等系統需要數千個圖像才能進行預測不同。這使其速度非常快,比 R-CNN 快 1000 倍以上,比 Fast R-CNN 快 100 倍。YOLO 設計可實現端到端訓練和實時速度,同時保持較高的平均精度。
有關完整 YOLO 系統的更多詳細信息,請參閱以下論文。
YOLOv4 是什麼?
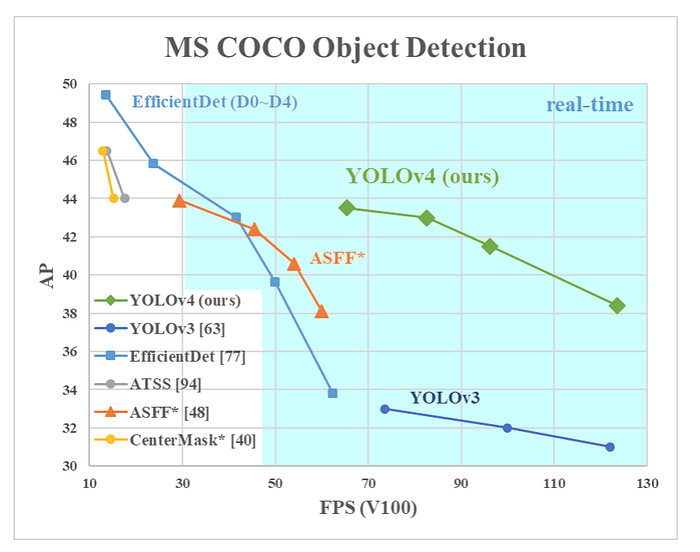
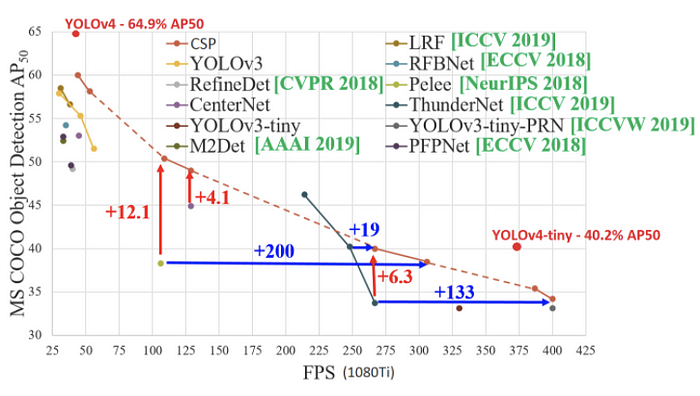
YOLOv4是一種對象檢測算法,是YOLOv3模型的演進。YOLOv4方法由Alexey Bochkovskiy 、 Chien -Yao Wang和Hong-Yuan Mark Liao創建。它的速度是 EfficientDet 的兩倍,但性能相當。此外,與YOLOv3相比,YOLOv4中的AP(平均精度)和FPS(每秒幀數)分別提高了10%和12%。YOLOv4的架構由 CSPDarknet53 作為主幹、空間金字塔池化附加模塊、PANet 路徑聚合頸部和YOLOv3頭。
YOLOv4使用了許多新功能並將其中一些功能結合起來以實現最先進的結果:MS COCO資料集的43.5% AP(65.7% AP50)在Tesla V100上以~65 FPS的實時速度。以下是YOLOv4使用的新特性:
- 加權殘差連接 (WRC)
- 跨級部分連接 (CSP)
- 交叉小批量標準化 (CmBN)
- 自我對抗訓練(SAT)
- 米甚激活
- 馬賽克資料增強
- DropBlock 正則化
- Complete Intersection over Union 損失(CIoU 損失)
YOLOv4-tiny 是什麼?
YOLOv4-tiny是 YOLOv4 的壓縮版本。提出基於YOLOv4 ,使網絡結構更簡單,減少參數,使其在移動和嵌入式設備上開髮變得可行。
我們可以使用 YOLOv4-tiny 進行更快的訓練和更快的檢測。它只有兩個 YOLO 頭,而 YOLOv4 中只有三個,它 是 從 29 個預訓練的捲積層訓練出來的,而 YOLOv4 是從 137 個預訓練的捲積層訓練出來的。
YOLOv4-tiny的FPS(每秒幀數)大約是 YOLOv4 的 8 倍。然而,在 MS COCO 資料集上測試時,YOLOv4-tiny 的準確度是 YOLOv4 的 2/3。
YOLOv4-tiny 模型在 RTX 2080Ti 上以 443 FPS 的速度實現了22.0% AP(42.0% AP50) ,而通過使用 TensorRT、batch size = 4 和 FP16-precision,YOLOv4-tiny 實現了 1774 FPS。
對於實時對象檢測,與YOLOv4相比, YOLOv4-tiny是更好的選擇,因為在使用實時對象檢測環境時,更快的推理時間比精度或準確度更重要。
我們在同一個 1500 個圖像掩碼資料集上訓練了YOLOv4和YOLOv4-tiny檢測器,其中YOLOv4平均損失在 6000 次迭代後達到約 0.68,YOLOv4-tiny平均損失在 6000 次迭代後達到約 0.15。

測試訓練有素的自定義檢測器
在使用網絡攝像頭進行實時對象檢測測試時,YOLOv4-tiny 比 YOLOv4 更好,因為它的推理時間要快得多。然而,在圖像和影片上進行測試時,YOLOv4 比 YOLOv4-tiny 更有效。
在圖像上測試檢測器
我們在相同的圖像上運行了兩個訓練有素的檢測器。在下面並排查看它們的輸出,左側是YOLOv4-tiny 預測圖像,右側是YOLOv4預測 圖像。
YOLOv4-小~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~YOLOv4
在影片上測試探測器
我還在同一影片上運行了兩個檢測器。您可以在下面觀看他們的影片編輯的並排比較。
我的自定義掩碼資料集
我們在下面的連結上分享了我的標記掩碼資料集。這是一個相對較小的資料集,但它將為您提供如何使用 YOLO 訓練您自己的自定義檢測器模型的良好開端。您可以找到具有更好質量圖像的更大資料集,然後自己標記它們。
bj.zip文件包含 1510個圖像以及它們的 YOLO 格式標記的文本文件。我已經標記了其中大約 1350 個,並從 Roboflow 下載了 149 個標記圖像
注意:這個資料集主要有特寫圖像(大約 1300 張)和很少的遠景圖像(大約 200 張)。如果你想下載更多遠景圖片,可以在線搜索資料集。有許多站點可以找到更多資料集。我在底部的Dataset Sources下給出了一些連結。您還可以將自己的圖像及其 YOLO 格式標記的文本文件添加到資料集中。
由於我的資料集主要有特寫圖像,因此圖像和影片中的特寫檢測非常好。另一方面,只有 200 張長鏡頭圖像為我們提供了長鏡頭檢測的平均性能。
這表明收集資料集並正確標記它們的過程是多麼重要。永遠記住這條規則:- Garbage In = Garbage Out。選擇和標記圖像是最重要的部分。嘗試找到高質量的圖像。資料的質量對確定結果的質量大有幫助。