Home >> Blog >> 在 Python 中讀取和寫入 CSV 文件
在 Python 中讀取和寫入 CSV 文件
讓我們面對現實吧:您需要通過鍵盤和控制台以外的方式將信息輸入和輸出您的程序。通過文本文件交換信息是在程序之間共享信息的常用方法。最流行的數據交換格式之一是 CSV 格式。但是你如何使用它?
讓我們弄清楚一件事:您不必(也不會)從頭開始構建自己的 CSV 解析器。您可以使用幾個完全可以接受的庫。Pythoncsv庫適用於大多數情況。如果您的工作需要大量數據或數值分析,則該pandas庫還具有 CSV 解析功能,它應該可以處理其餘部分。
在本文中,您將學習如何使用 Python 從文本文件中讀取、處理和解析 CSV。您將了解 CSV 文件的工作原理,了解csvPython 中內置的最重要的庫,並了解如何使用該pandas庫進行 CSV 解析。
所以讓我們開始吧!
什麼是 CSV 文件?
CSV 文件(逗號分隔值文件)是一種純文本文件,它使用特定的結構來排列表格數據。因為它是一個純文本文件,所以它只能包含實際的文本數據——換句話說,就是可打印的ASCII或Unicode字符。
CSV 文件的結構由其名稱給出。通常,CSV 文件使用逗號分隔每個特定數據值。這是該結構的樣子:
CSV
column 1 name,column 2 name, column 3 name
first row data 1,first row data 2,first row data 3
second row data 1,second row data 2,second row data 3
注意每條數據是如何用逗號分隔的。通常,第一行標識每條數據——換句話說,就是數據列的名稱。之後的每一行都是實際數據,僅受文件大小限制。
通常,分隔符稱為分隔符,而逗號不是唯一使用的。其他流行的分隔符包括製表符 ( \t)、冒號 ( :) 和分號 ( ;) 字符。正確解析 CSV 文件需要我們知道正在使用哪個分隔符。
CSV 文件從何而來?
CSV 文件通常由處理大量數據的程序創建。它們是從電子表格和數據庫中導出數據以及在其他程序中導入或使用數據的便捷方式。例如,您可以將數據挖掘程序的結果導出為 CSV 文件,然後將其導入電子表格以分析數據、生成圖表以進行演示或準備發布報告。
CSV 文件非常容易以編程方式處理。任何支持文本文件輸入和字符串操作的語言(如 Python)都可以直接處理 CSV 文件。
使用 Python 的內置 CSV 庫解析 CSV 文件
該csv庫提供讀取和寫入 CSV 文件的功能。專為使用 Excel 生成的 CSV 文件開箱即用而設計,它很容易適應各種 CSV 格式。該csv庫包含對象和其他代碼,用於從 CSV 文件讀取、寫入和處理數據。
讀取 CSV 文件csv
reader使用對象完成從 CSV 文件中的讀取。CSV 文件使用 Python 的內置open()函數作為文本文件打開,該函數返回一個文件對象。然後將其傳遞給reader執行繁重工作的 。
這是employee_birthday.txt文件:
TCSV
name,department,birthday month
John Smith,Accounting,November
Erica Meyers,IT,March
這是閱讀它的代碼:
這將產生以下輸出:
import csv
with open('employee_birthday.txt') as csv_file:
csv_reader = csv.reader(csv_file, delimiter=',')
line_count = 0
for row in csv_reader:
if line_count == 0:
print(f'Column names are {", ".join(row)}')
line_count += 1
else:
print(f'\t{row[0]} works in the {row[1]} department, and was born in {row[2]}.')
line_count += 1
print(f'Processed {line_count} lines.')
這將產生以下輸出:
Shell
Column names are name, department, birthday month
John Smith works in the Accounting department, and was born in November.
Erica Meyers works in the IT department, and was born in March.
Processed 3 lines.
返回的每一行reader都是一個元素列表,String其中包含通過刪除分隔符找到的數據。返回的第一行包含以特殊方式處理的列名。
將 CSV 文件讀入字典csv
除了處理單個String元素的列表,您還可以將 CSV 數據直接讀入字典(從技術上講,是Ordered Dictionary)。
同樣,我們的輸入文件employee_birthday.txt如下:
CSV
name,department,birthday month
John Smith,Accounting,November
Erica Meyers,IT,March
這是這次將其作為字典讀取的代碼:
Python
import csv
with open('employee_birthday.txt', mode='r') as csv_file:
csv_reader = csv.DictReader(csv_file)
line_count = 0
for row in csv_reader:
if line_count == 0:
print(f'Column names are {", ".join(row)}')
line_count += 1
print(f'\t{row["name"]} works in the {row["department"]} department, and was born in {row["birthday month"]}.')
line_count += 1
print(f'Processed {line_count} lines.')
這將產生與以前相同的輸出:
Column names are name, department, birthday month
John Smith works in the Accounting department, and was born in November.
Erica Meyers works in the IT department, and was born in March.
Processed 3 lines.
字典鍵
可選的 Python CSVreader參數
該reader對象可以通過指定附加參數來處理不同樣式的 CSV 文件,其中一些參數如下所示:
- delimiter指定用於分隔每個字段的字符。默認值為逗號 ( ',')。
- quotechar指定用於包圍包含分隔符的字段的字符。默認值為雙引號 ( ' " ')。
- escapechar指定用於轉義分隔符的字符,以防不使用引號。默認是沒有轉義字符。
這些參數值得更多解釋。假設您正在使用以下employee_addresses.txt文件:
name,address,date joined
john smith,1132 Anywhere Lane Hoboken NJ, 07030,Jan 4
erica meyers,1234 Smith Lane Hoboken NJ, 07030,March 2
此 CSV 文件包含三個字段:name、address和date joined,它們由逗號分隔。問題是該address字段的數據還包含一個逗號來表示郵政編碼。
有三種不同的方法來處理這種情況:
- 使用不同的分隔符.
這樣,逗號可以安全地用於數據本身。您使用delimiter可選參數來指定新的分隔符。
- 將數據括在引號
中 您選擇的分隔符的特殊性質在帶引號的字符串中會被忽略。quotechar因此,您可以使用可選參數指定用於引用的字符。只要該字符也沒有出現在數據中,就可以了。
- 轉義數據中的分隔符
轉義字符的工作方式與它們在格式字符串中的作用一樣,使對被轉義字符(在本例中為分隔符)的解釋無效。如果使用轉義字符,則必須使用escapechar可選參數指定。
用csv
writer您還可以使用對象和方法寫入 CSV 文件.write_row():
import csv
with open('employee_file.csv', mode='w') as employee_file:
employee_writer = csv.writer(employee_file, delimiter=',', quotechar='"', quoting=csv.QUOTE_MINIMAL)
employee_writer.writerow(['John Smith', 'Accounting', 'November'])
employee_writer.writerow(['Erica Meyers', 'IT', 'March'])
quotechar可選參數告訴寫入時使用writer哪個字符來引用字段。但是,是否使用引用由quoting可選參數確定:
- 如果quoting設置為csv.QUOTE_MINIMAL,則僅當字段包含或.writerow()時才會引用字段。這是默認情況。delimiterquotechar
- 如果quoting設置為csv.QUOTE_ALL,.writerow()則將引用所有字段。
- 如果quoting設置為csv.QUOTE_NONNUMERIC,.writerow()則將引用包含文本數據的所有字段並將所有數字字段轉換為float數據類型。
- 如果quoting設置為csv.QUOTE_NONE,.writerow()則將轉義分隔符而不是引用它們。escapechar在這種情況下,您還必須為可選參數提供一個值。
以純文本形式讀回文件表明該文件是按如下方式創建的:
John Smith,Accounting,November
Erica Meyers,IT,March
從字典中寫入 CSV 文件csv
由於您可以將我們的數據讀入字典,因此您也應該能夠將其從字典中寫出來是公平的:
import csv
with open('employee_file2.csv', mode='w') as csv_file:
fieldnames = ['emp_name', 'dept', 'birth_month']
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
writer.writeheader()
writer.writerow({'emp_name': 'John Smith', 'dept': 'Accounting', 'birth_month': 'November'})
writer.writerow({'emp_name': 'Erica Meyers', 'dept': 'IT', 'birth_month': 'March'})
與 不同的是,在編寫字典時需要DictReader該參數。fieldnames這是有道理的,當您考慮它時:如果沒有 列表fieldnames,DictWriter則無法知道使用哪些鍵從您的字典中檢索值。它還使用輸入鍵fieldnames將第一行寫為列名。
上面的代碼生成以下輸出文件:
CSV
emp_name,dept,birth_month
John Smith,Accounting,November
Erica Meyers,IT,March
pandas使用庫解析 CSV 文件
當然,Python CSV 庫並不是鎮上唯一的遊戲。也可以讀取 CSV 文件pandas。如果您有大量數據要分析,強烈建議使用。
pandas是一個開源 Python 庫,提供高性能的數據分析工具和易於使用的數據結構。pandas可用於所有 Python 安裝,但它是Anaconda發行版的關鍵部分,並且在Jupyter 筆記本中運行得非常好,可以共享數據、代碼、分析結果、可視化和敘述性文本。
安裝pandas及其依賴項Anaconda很容易完成:
Shell$ conda install pandas
與使用pip/pipenv其他 Python 安裝一樣:
Shell$ pip install pandas
我們不會深入研究如何pandas工作或如何使用它的細節。如需深入了解如何使用pandas讀取和分析大型數據集,請查看Shantnu Tiwari關於在 pandas 中處理大型 Excel 文件的精彩文章。
讀取 CSV 文件pandas
為了展示pandasCSV 功能的一些強大功能,我創建了一個稍微複雜的文件來讀取,名為hrdata.csv. 它包含有關公司員工的數據:
CSVName,Hire Date,Salary,Sick Days remaining
Graham Chapman,03/15/14,50000.00,10
John Cleese,06/01/15,65000.00,8
Eric Idle,05/12/14,45000.00,10
Terry Jones,11/01/13,70000.00,3
Terry Gilliam,08/12/14,48000.00,7
Michael Palin,05/23/13,66000.00,8
將 CSV 讀入 apandas DataFrame是快速而直接的:
Tython
import pandas
df = pandas.read_csv('hrdata.csv')
print(df)
就是這樣:三行代碼,其中只有一個在做實際的工作。pandas.read_csv()打開、分析和讀取提供的 CSV 文件,並將數據存儲在DataFrame中。DataFrame在以下輸出中打印結果:
這裡有幾點值得注意:
- 首先,pandas認識到 CSV 的第一行包含列名,並自動使用它們。我稱之為善良。
- 但是,pandas也在DataFrame. 那是因為我們沒有告訴它我們的索引應該是什麼。
- 此外,如果您查看我們的 columns 的數據類型,您會看到pandas已經正確地將SalaryandSick Days remaining列轉換為數字,但該Hire Date列仍然是 a String。這在交互模式下很容易確認:
Python
>>> print(type(df['Hire Date'][0]))
< class 'str'>
讓我們一次一個地解決這些問題。要使用不同的列作為DataFrame索引,請添加index_col可選參數:
Python
import pandas
df = pandas.read_csv('hrdata.csv', index_col='Name')
print(df)
現在該Name字段是我們的DataFrame索引:
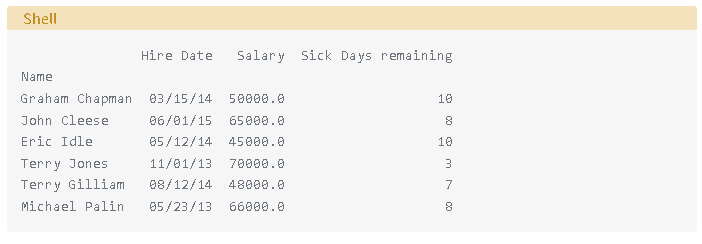
注意輸出的不同:
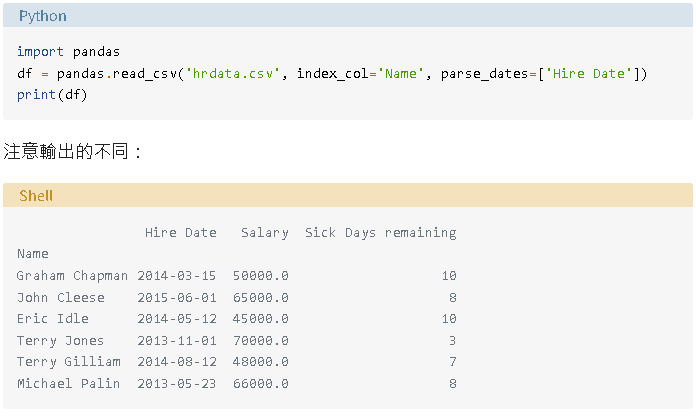
現在日期格式正確,在交互模式下很容易確認:

如果您的 CSV 文件在第一行中沒有列名,您可以使用names可選參數來提供列名列表。如果要覆蓋第一行中提供的列名,也可以使用它。在這種情況下,您還必須告訴pandas.read_csv()使用header=0可選參數忽略現有的列名:

請注意,由於列名已更改,因此在index_col和parse_dates可選參數中指定的列也必須更改。這現在會產生以下輸出:
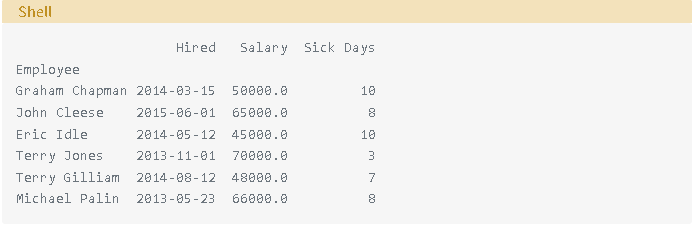
用pandas
當然,如果您不能pandas再次取出數據,那對您沒有多大好處。將 a 寫入DataFrameCSV 文件就像讀入一樣簡單。讓我們將具有新列名的數據寫入新的 CSV 文件:

此代碼與上面的讀取代碼之間的唯一區別是print(df)調用被替換為df.to_csv(),提供了文件名。新的 CSV 文件如下所示:

結論
如果您了解讀取 CSV 文件的基礎知識,那麼當您需要處理導入數據時,您將永遠不會措手不及。大多數 CSV 讀取、處理和寫入任務都可以通過基本的csvPython 庫輕鬆處理。如果您有大量數據要讀取和處理,該pandas庫還提供快速簡便的 CSV 處理功能。
還有其他方法可以解析文本文件嗎?當然!像ANTLR、PLY和PlyPlus這樣的庫都可以處理繁重的解析,如果簡單的String操作不起作用,總是有正則表達式。